-
CUDA를 이용한 병렬 프로그래밍 (1)카테고리 없음 2023. 12. 28. 22:47
CUDA?
a parallel computing platform and application programming interface(API), GPGPU
CUDA는 C, C++, Python 등과 같은 언어에서 GPU로 연산을 할 수 있게 해주는 일종의 Code Extension이다.
GPGPU?
일반적으로 GPU에서 컴퓨터 그래픽스 관련 작업만 처리했지만
CPU에서 주로 처리했던 응용 프로그램의 계산에 사용하는 기술Example: Hello World
#include <stdio.h> __global__ void hello_world(void) { printf("Hello World\n"); } int main (void) { hello_world<<<1,5>>>(); cudaDeviceReset(); return 0; }__global__, __device__
host는 시스템에서 사용 가능한 CPU를 의미
device는 시스템에서 사용 가능한 GPU를 의미
- global
- device에서만 실행될 수 있다.
- host에서만
__global__이 붙은 함수를 실행할 수 있다. - 함수의 리턴형은 void이다.
__global__이 붙은 함수는 실행 시에execution configuration을 명시해야 한다.
- device
- device에서만 실행될 수 있다.
- device에서만
__device__가 붙은 함수를 실행할 수 있다.
Excution Configuration
__global__이 붙은 function을 kernel function(커널 함수)라고 한다.이 kernel이 실행될 때 여러 개의 Thread로 구성된 그룹을 할당받아 작업을 처리한다.
hello_world<<<1,5>>>(); #OUTPUT: Hello World Hello World Hello World Hello World Hello World위 kernel 함수는 1개의 Block에 5개의 Thread를 사용하여 hello_world라는 function을 각각 실행한다.
Grid, Block, Thread
하나의 kernel이 실행될 때, 하나의 grid가 할당된다.
grid는 여러 개의 block으로 이루어져 있으며,
block 또한 여러 개의 thread로 이루어져 있다.

Grid, Block, Thread 각 thread는 고유한 index를 갖는데 관련된 공식은 다음과 같다.
Index = threadIdx.x + blockIdx.x * blockDim.xblockDim은 block안에 thread가 몇 개 있는지를 나타내고
blockIdx는 grid안에서 몇 번째 block인지를 표현한다.
threadIdx는 block내에서 몇 번째 thread인지를 나타냄으로써
각 thread에 대한 고유한 Index를 알 수 있다.
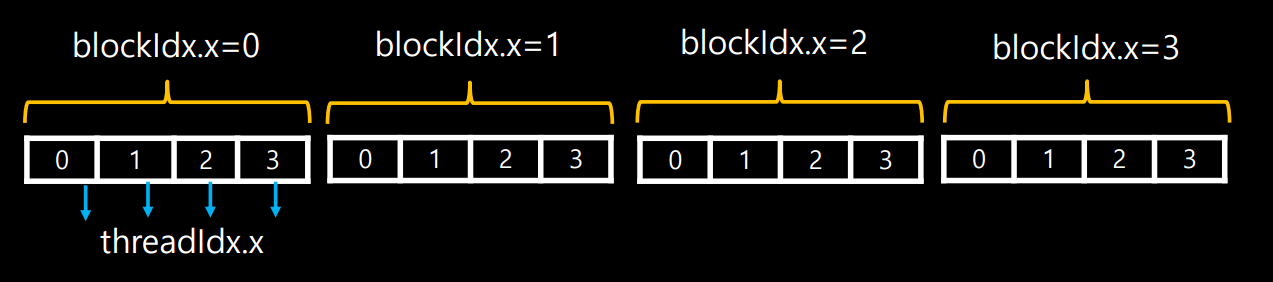
Thread Index Limitation of threads and blocks
- threadIdx.x * threadIdx.y * threadIdx.z < 1024
- threadIdx.x or threadIdx.y< 1024; threadIdx.z < 64
- blockIdx.x < 2147483647; blockIdx.y or blockIdx.z < 65535
이 제약 조건을 어기도록 block당 thread 개수를 1030개로 설정한 결과
에러는 나지 않았지만 정상적으로 실행되지는 않았다..
이러한 제약 조건이 왜 생겼는가..에 대해서 찾아보았지만 명확하게 나오는 것은 없었다…
Processing flow on CUDA
CUDA 프로그램을 실행하면
- Host Memory에 있는 데이터를 Device Memory로 복사한다.
- Device Memory에서 연산을 수행한다.
- Device Memory에서 연산한 데이터를 다시 Host Memory로 복사한다.
이 예시는 두 벡터 a, b를 더하여 c를 구하는 코드이다.
#include <stdio.h> const int N = 10; // Size of the vectors // CUDA kernel to add two vectors __global__ void vectorAddition(float *a, float *b, float *c, int n) { int idx = threadIdx.x + blockDim.x * blockIdx.x; // Check if the thread index is within the vector size if (idx < n) { c[idx] = a[idx] + b[idx]; } } int main() { // Vector size int size = N * sizeof(float); // Host vectors float *h_a, *h_b, *h_c; // Allocate memory for host vectors (1) h_a = (float*)malloc(size); h_b = (float*)malloc(size); h_c = (float*)malloc(size); // Initialize host vectors for (int i = 0; i < N; i++) { h_a[i] = static_cast<float>(i); h_b[i] = static_cast<float>(2 * i); } // Device vectors float *d_a, *d_b, *d_c; // Allocate memory for device vectors (2) cudaMalloc((void**)&d_a, size); cudaMalloc((void**)&d_b, size); cudaMalloc((void**)&d_c, size); // Copy host vectors to device (3) cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice); cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice); // Define the grid and block dimensions int blockSize = 256; int gridSize = (N + blockSize - 1) / blockSize; // Launch the kernel (4) vectorAddition<<<gridSize, blockSize>>>(d_a, d_b, d_c, N); // Wait for the kernel to finish (5) cudaDeviceSynchronize(); // Copy the result from device to host (6) cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost); // Print the result printf("Result vector:\n"); for (int i = 0; i < N; i++) { printf("%.2f ", h_c[i]); } printf("\n"); // Free memory free(h_a); free(h_b); free(h_c); cudaFree(d_a); cudaFree(d_b); cudaFree(d_c); return 0; }(1) : host 변수 메모리 할당
(2) : device 변수 메모리 할당(
cudaMalloc)(3) : Host Memory에 있는 데이터를 Device Memory로 복사(
cudaMemcpy)(4) : kernel 실행
(5) : Device에서 모든 연산을 끝낼 때까지 기다린다.
만약 이 부분이 없다면 연산하기 전에 main function이 끝나게 된다.(
cudaDeviceSynchronize)(6) : Device Memory에서 연산한 데이터를 Host Memory로 복사(
cudaMemcpy)Unified Memory
앞서 봤던 Communicate Memory의 단점은
CPU와 GPU가 데이터를 주고받는 데에 생기는 OverHead가 크다는 것이다.
연산 속도를 아무리 줄여도 데이터를 주고받는 데 생기는 딜레이 때문에 속도가 느려질 수 있다.
이를 보완하기 위해서 Unified Memory 개념이 나왔는데
host memory와 device memory가 서로 같은 메모리를 사용하여
이전과 같이 host에서 device로 device에서 host로 데이터를 주고받지 않아도 된다.
위 예시 코드는 Unified Memory를 사용하여 두 벡터 a, b를 더하여 c를 구하는 코드이다.
#include <stdio.h> const int N = 10; // Size of the vectors // CUDA kernel to add two vectors __global__ void vectorAddition(float *c, const float *a, const float *b, int n) { int idx = threadIdx.x + blockDim.x * blockIdx.x; // Check if the thread index is within the vector size if (idx < n) { c[idx] = a[idx] + b[idx]; } } int main() { // Vector size int size = N * sizeof(float); // Unified memory pointers float *a, *b, *c; // Allocate unified memory cudaMallocManaged(&a, size); cudaMallocManaged(&b, size); cudaMallocManaged(&c, size); // Initialize vectors for (int i = 0; i < N; i++) { a[i] = static_cast<float>(i); b[i] = static_cast<float>(2 * i); } // Define the grid and block dimensions int blockSize = 256; int gridSize = (N + blockSize - 1) / blockSize; // Launch the kernel vectorAddition<<<gridSize, blockSize>>>(c, a, b, N); // Wait for the kernel to finish cudaDeviceSynchronize(); // Print the result printf("Result vector:\n"); for (int i = 0; i < N; i++) { printf("%.2f ", c[i]); } printf("\n"); // Free unified memory cudaFree(a); cudaFree(b); cudaFree(c); return 0; }Communicate Memory 예시 코드와 다른 점은
- host, device에 상관없이 a, b, c로만 변수를 선언하였다.
cudaMalloc대신,cudaMallocManaged를 사용하여 메모리를 할당하였다.
Communicate Memory VS Unified Memory
초기에는 Unified Memory 방식을 사용하되,
프로그램의 계산량, 규모가 커지면 Communicate Memory로 변경하는 것을 권장
Ref.
2023 KISTI HPCㆍAI 겨울학교
- global