-
Scailability, Operations카테고리 없음 2025. 4. 2. 23:51
4주차 Database Study
데이터베이스 확장(Database Scaling)
데이터베이스의 성능을 향상시키는 방법, Scale-Up과 Scale-Out이 있음
데이터베이스에서의 Scale-Up / Scale-Out
Scale-Up : 데이터베이스의 기존 서버의 성능을 향상 ex) CPU, Memory, Disk 등
- 장점 : 데이터베이스 하나로 처리하면되므로 유지보수 용이
- 단점 : 비용이 올라갈수록 성능향상을 보장하지 않음 -> Scale Up을 통해 확장하는 방식은 한계가 존재
Scale Out : 데이터베이스의 개수를 늘리는 방법
- 장점 : 확장성, 고가용성
- 단점 : 유지보수가 힘듬, 여러 데이터베이스 간의 데이터일관성을 맞추기 위해서 노력
샤딩(Sharding)
- 데이터를 나누어 여러 서버에 분산 저장하는 방법
- 샤드라는 최소 단위로 구성
샤딩의 장점
- 검색 쿼리 속도 향상
- 백업 및 복구 용이
샤드를 사용하는 예시
사용자 ID와 같은 컬럼 값을 기준으로 데이터를 나누고 각각 다른 데이터베이스에 저장
사용자 ID 1 ~ 1000 → DB1 저장
사용자 ID 1001 ~ 2000 → DB2 저장
사용자 ID 2001 ~ 3000 → DB3 저장
샤드를 사용하기 좋은 경우
데이터베이스의 부하가 예상되는 경우에 사용될 수 있음
- 데이터베이스의 용량이 클 경우 = 많은 데이터
- 트래픽이 과도하게 몰릴 경우
샤드에서 라우팅을 구현하는 방법
- 해시 값 계산
- 범위 기반
파티셔닝(Partitioning)
- 데이터를 여러 부분으로 나누어 저장하는 것
- 파티션이라는 단위로 구성
파티셔닝의 장점
- 검색 쿼리 속도 향상
- 백업 및 복구 용이
파티셔닝의 종류
수평 파티셔닝
키를 기준으로 행 단위로 데이터를 나눔
사용자 ID 1 ~ 1000 → 파티션1
사용자 ID 1001 ~ 2000 → 파티션2
사용자 ID 2001 ~ 3000 → 파티션3수직 파티셔닝
키를 기준으로 열 단위로 데이터를 나눔
이름, 전화번호 → 파티션1
나이, 주소 → 파티션2파티셔닝 VS 샤딩
파티셔닝은 하나의 데이터베이스에서 → 성능 최적화
샤딩은 여러 개의 데이터베이스에 분산 저장 → 성능 최적화, 확장성레플리케이션(Replication)
Master-Slave
- Master는 쓰기 작업(INSERT, UPDATE, DELETE), Slave는 읽기 작업(SELECT)을 처리
- Master에서의 변경사항을 Slave에 복제
- 쓰기와 읽기 작업을 분리하여 데이터베이스 부하를 분산
Master에서 Slave로 변경사항을 복제하는 방법
동기식
- 장점 : 데이터 일관성을 보장
- 단점 : 시간, 쓰기작업 + 동기화시간
비동기식
- 장점 : 동기화 시간을 최소화
- 단점 : 시간차에 따라서 데이터 불균형이 발생할 수 있음
Connection Pool
데이터베이스에 커넥션을 미리 생성해놓고 관리하는 방법
Connection Pool을 사용하는 이유
- Connection 생명주기 : 생성 → 작업 → 소멸
- 하지만 커넥션 생성과 소멸에 들어가는 비용이 발생
- 미리 생성해두고 작업 후 다시 반납하여 재 사용
Connection Pool의 장점
- 성능 향상 : 생성 소멸 시간을 단축
- 부하 예방 : 최대 커넥션 개수 제한으로 데이터베이스가 과부하 걸리는 것을 방지
Zero-downtime 배포
다운타임(=서비스 중단 시간)없이 배포하는 방법
Zero-downtime 배포 종류
Blue-Green 배포
- 두 개의 환경(Blue, Green)을 준비하고 별도로 배포
- 예를 들어서 Blue로 운영하다가 새로운 배포를 Green에 배포하고 트래픽을 전환
- 장점 : 문제 발생시, 이전 환경으로 바로 롤백
- 단점 : 인프라 낭비
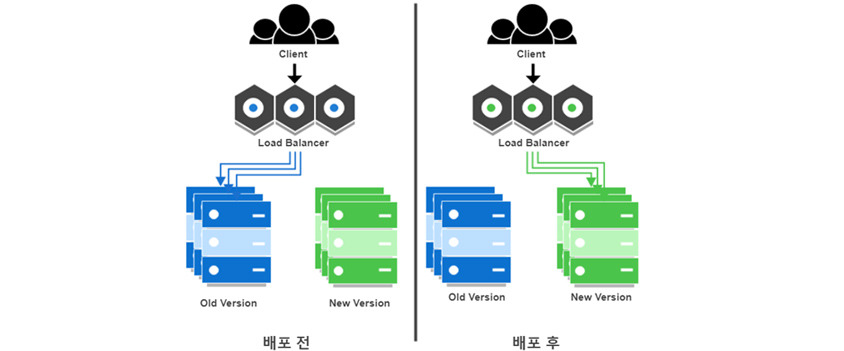
https://www.samsungsds.com/kr/insights/1256264_4627.html Rolling Deployment
- 하나씩 업데이트 하는 방식 → 인스턴스 한개씩
- 장점 : 하나씩 업데이트하므로 다른 인스턴스들은 계속 사용 가능
- 단점 : 하나씩 배포해서 시간오래걸림, 배포 도중 버전 안맞는 경우 발생가능
Canary Deployment
- 소수의 사용자 먼저 배포하고 점진적으로 배포 확대
- 5~10%의 사용자에게 새로운 버전으로 테스트하고 이상이 없다면 전체 사용자에게 확대
Failover 전략
Failover란 장애가 발생했을 때, 예비 시스템으로 자동 전환되는 기법
Failover 전략의 종류
Active-Active
운영상황에서 둘다 작업을 처리하다가, 장애상황에서 한쪽을 대신하게 됨
장점 : 고가용성, 부하분산
단점 : 데이터 동기화, 운영 비용
Active-Standby
운영상황에는 Active만 작업을 처리하다가, 장애상황에서 Standby가 Active를 대신하게 됨
장점 : 비용이 상대적으로 낮고 구조가 단순함
단점 : Standby는 장애상황에서만 작동하기 때문에 자원 낭비
데이터베이스 모니터링 주요 지표